バックアップ重複排除テクノロジーは、データをバックアップや転送するときに重複するデータブロックを排除して、ストレージコストとネットワーク帯域幅の使用率を削減するのに役立ちます。
重複排除は、次のことに役立ちます。
- 固有のデータのみを格納することで、ストレージスペースの使用量を削減
- 転送されるデータが少なくなるため、ネットワーク負荷が軽減され、生産タスクの帯域幅が広くなる
- データ重複排除固有のハードウェアに投資する必要性を排除
ただし、重複排除されたストレージにはRAMやCPUなどのコンピューティングリソースがさらに必要になる可能性があります。 一部のユースケースでは、従来の重複排除されていないストレージの方が、重複排除よりも費用対効果が高い場合もあります。 重複排除を実装する前に、常にニーズとインフラストラクチャを分析しなければなりません。
バックアップストレージの課題
私たちはビッグデータの時代に生きています。
1990年、パーソナルコンピュータのハードディスクは10メガバイトでした。 現在、マルチテラバイトディスクが一般的です。現在人類は文明の夜明けから2000年までに作成されたのと同じくらい多くのデータ量を10分ごとに作成し続けています。
これらすべてのデータを保護し、バックアップしなければなりません。 さもなければ自分の会社の資金、評判、時間などの資産を失うかもしれず、さらにビジネス全体さえもシャットダウンしてしまうかもしれないのです。

ただし、AcronisとIDC(International Data Corporation)が調査した中小企業(SMB)の75%が、データが完全に保護されていないと認めています。 「膨大な量のデータ」がその主な理由の1つでした。
たとえば、デスクトップとラップトップを使用している400人の従業員を抱える企業を見てみましょう。 平均的なラップトップはハードディスクに50から数百ギガバイトのデータを保持できます。 PCには、20〜150 TB(テラバイト)のデータがあります。 2:1の圧縮率では、バックアップ管理者はフルバックアップごとに10〜75TBの間でプロビジョニングを行う必要があり、さらに増分および差分バックアップ用のスペースを増やす必要もあります。 結局、この企業はPCのバックアップだけで1ペタバイトものストレージが必要となるかもしれません。
この企業がPCのバックアップのために、高価な記憶装置に投資していると仮定してみましょう。 次の大きな課題は、PCのデータをストレージにバックアップすることです。 100メガビット(メガビット)ネットワークは、毎秒10メガバイトのデータしか転送できません。 この速度では、100 Mbitネットワーク上で10〜75 TBのデータを転送するのにフルバックアップに2〜3週間もかかってしまいます。
その上、すべてのデスクトップには、同じウィンドウ操作システム、同じアプリケーション、および同じデータの多数のコピーがあります。 同じデータを同じストレージに複数回格納して転送すると、時間とリソースが無駄です。 バックアップソリューションが固有のデータのみを転送して保存する場合、同社はストレージ容量とネットワーク要件を最大50倍まで削減できます。 重複排除で企業はこれらの節約ができます。
バックアップ重複排除とは
バックアップ重複排除は、データの繰り返しを検出し、同一のデータを一度だけ保存することにより記憶領域を最小限に抑えます。 重複排除によってネットワークの負荷も軽減されます。以前にバックアップされたデータの重複はネットワーク経由でストレージに転送されることすらありません。
重複排除を有効にすると、バックアップソリューションによってバックアップが重複排除され、管理対象ストレージに保存されます。 重複排除が有効になっているストレージの場所は、重複排除ストレージと呼ばれています。
重複排除は、ファイル、サブファイル(ファイルの一部)、またはブロックレベルで動作し、通常はバックアップソリューションでサポートされているすべてのオペレーティングシステムで機能します。
次のものを作成すると、重複排除で最大の結果が得られます:
- オペレーティングシステム(OS)、仮想マシン(VM)、標準イメージから展開されたものなど、さまざまなソースからの類似データのフルバックアップ、標準イメージからデプロイされたアプリケーション
- 異なるソースから得た類似データの増分バックアップ。 たとえば、OSアップデートを複数のシステムに展開して増分バックアップを実行する場合
- 以前に同じ重複排除ストレージにバックアップしたシステムのフルバックアップ
- データは変更がないが、データの場所が変更された増分バックアップ。 たとえば、ファイルなどのデータがネットワーク上または1つのシステム内を循環して新しい場所に表示される場合など
バックアップ重複排除の仕組み
重複排除中、バックアップデータはブロックに分割されます。 各ブロックは一意性が特別なデータベースを介してチェックされます。このデータベースは保存されているすべてのブロックのチェックサムを追跡します。 固有ブロックがストレージに送信され、重複はスキップされます。
たとえば、10台の仮想マシンを重複排除したストレージにバックアップし、そのうち5台に同じブロックが見つかった場合、このブロックの1つのコピーのみが送信と保存されます。
重複ブロックをスキップするこのアルゴリズムは、記憶領域を節約し、ネットワークトラフィックを最小限に抑えます。
ソースでの重複排除
重複排除ストレージへのバックアップを実行するとき、バックアップソリューションは各データブロックのフィンガープリントやチェックサムを計算します。このフィンガープリントやチェックサムは、ハッシュ値と呼ばれます。
バックアップソリューションでは、固定サイズか可変サイズのブロックをサポートしていることがあります。 固定サイズのブロック重複排除では効果がないことが証明されています。ブロックサイズが小さい場合、大量のRAMとCPUを消費します。 ブロックサイズが大きい場合は、重複排除率がかなり低くなります。
最新の最新のバックアップソリューションのほとんどは、可変サイズのブロック重複排除を提供し、ブロックサイズを調整して重複排除率を最大化しながら、RAMとCPUの使用量を削減します。
データブロックをストレージに送信する前に、バックアップソリューションはストレージシステムにクエリし、ブロックのハッシュ値がすでに格納されているかどうかを判断します。格納されてあれば、ソリューションはハッシュ値のみを送信します。それ以外の場合は、ブロック自体を送信します。
暗号化されたファイルや非標準サイズのディスクブロックなど、一部のデータは重複排除できません。 この場合、ソリューションはハッシュ値を計算せずにこのデータを常にストレージに転送します。
ターゲットでの重複排除
重複排除ストレージへのバックアップが完了すると、ストレージシステムはストレージ側の重複排除を実行します。 通常、このプロセスは次のように機能します。
- データブロックは、バックアップファイルからストレージ内の特別なファイル(重複排除データストア)に移動されます。 重複ブロックは一度だけ格納されます。
- ハッシュ値とデータブロックへのリンクは重複排除データベースに保存されるため、データを簡単に再構築(戻す)できます。
その結果、データストアには多数の固有のデータブロックが含まれることになります。 各ブロックには、バックアップからの1つ以上の参照が含まれます。 参照は重複排除データベースに記録されます。
下の図は、ターゲットでの重複排除の結果を示しています。
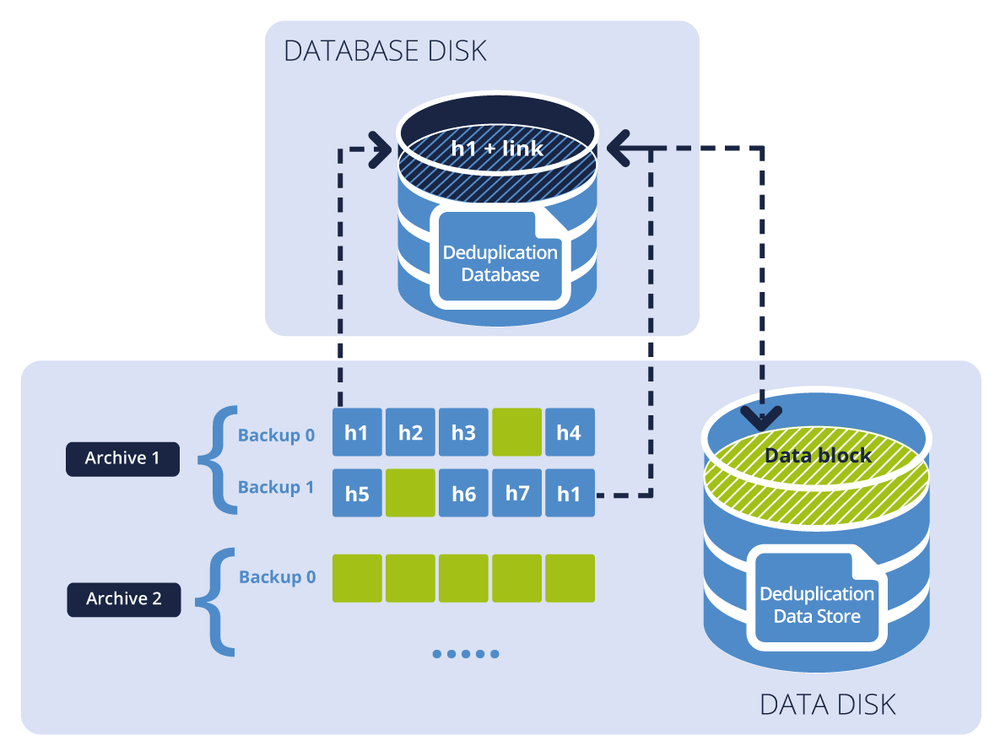
図では2つのバックアップアーカイブを示しています。 それぞれに個別のバックアップセットがあり、アーカイブのh1からh7(青いブロックで表示)には、バックアップファイルに格納されているハッシュ値が含まれています。 緑色のブロックは重複排除できないデータブロックです。 アーカイブ2はデータ(緑色)ブロックのみを含んでおり、それは暗号化されています。 その結果、重複排除データベースには、重複排除可能なブロックのハッシュ値が含まれ、重複排除データストアには、アーカイブ1とアーカイブ2の両方のデータブロックが含まれています。
復旧
リカバリ中に、バックアップソリューションエージェントはストレージにデータを求めます。 ストレージシステムはストレージからバックアップデータを読み取り、ブロックが重複排除データストアで参照されている場合、ストレージシステムはそこからデータを読み取ります。 エージェントの場合、リカバリプロセスは透過的で重複排除から独立しています。
孤立データブロックの削除
1つ以上のバックアップがストレージから削除された後(手動や保持ルールなどで)、データストアにブロックが含まれていることがあります。これらのブロックは、どのバックアップからも参照されなくなります。 これらの孤立ブロックは、ストレージシステムによって実行される特別なスケジュールタスクによって削除します。
これがどのように機能するのかは、 まずストレージシステムはストレージ内のすべてのバックアップをスキャンし、すべての参照を使用済みとしてマークします(適切なハッシュは重複排除データベースで使用済みとしてマークされます)。 次に、ストレージシステムは未使用のブロックをすべて削除します。
このプロセスは追加のシステムリソースが必要になるかもしれません。 そのため、このタスクは通常、十分な量のデータがストレージに蓄積されている場合にのみ実行されます。
圧縮と暗号化
バックアップソリューションエージェントは通常、バックアップされたデータをサーバーに送信する前に圧縮します。 各データブロックのハッシュ値は、圧縮前に計算されます。 これにより2つの等しいブロックが異なるレベルの圧縮で圧縮された場合でも、それらは重複として認識します。
ソース側で暗号化されたバックアップは、セキュリティ上の理由から重複排除されません。
暗号化と重複排除の両方を活用するには、バックアップソリューションで管理対象ストレージ自体の暗号化をサポートする必要があります。この場合、リカバリ中に、データはストレージ固有の暗号化キーを使用してストレージシステムによって透過的に復号化されます。記憶媒体が不正な者によって盗まれたりアクセスされたりすると、記憶システムにアクセスすることなしに記憶を解読はできません。
重複排除を使用する必要がある場合
重複排除率が最も低い値になると、重複排除が最も大きな影響を及ぼします。重複排除率の計算式は次の通りです。
重複排除率=一意のデータの割合+(1 - 固有データの割合)/マシン数
この意味は以下の二つのことを示します:
- 重複排除は、各マシンに多数の重複データがある環境で最も効果がある。
- 重複排除は、類似のマシン/仮想マシン/アプリケーションを多数バックアップする必要がある環境で最も効果がある。
さらに、重複排除は、ワイドエリアネットワーク(WAN)を最適化しようとしているときなどの他のシナリオでも役立ちます。
いくつかの典型的なユースケースを見てみましょう。
ユースケース1:同じようなマシンがある大きな環境
環境
バックアップする必要がある同様のワークステーションが100台ある。ワークステーションは当初、ディスクイメージングシステム展開ソリューションを使用して展開されていた。
重複排除効果
ワークステーションは単一のイメージから展開されたため、すべてのマシンで実行されるオペレーティングシステムと汎用アプリケーションは同一です。 その結果、多くの重複データがあります。 ワークステーションが多数あるため、重複排除はさらに効果的です。
結論
このシナリオでは、重複排除はストレージ容量を最小限に抑え、ストレージコストを節約するため、非常に効果的です。
ユースケース2:WAN最適化
環境
本社の40台の同じようなワークステーションを遠隔地にバックアップする必要がある。
重複排除効果
ワークステーションが単一のイメージから展開されたかどうかは不明。 ただし、同様の種類のオペレーティングシステムには、よく似たファイルが多数ある。 各PC上のデータの50%が一意であると仮定すると重複排除はかなり有効です。
重複排除率= 50%+(100% - 50%)/ 40 = 51.25%
ストレージとネットワークトラフィックのおおよその節約量は48.75%(100% - 51.25%)です。つまり、重複排除によってこれらの要件がほぼ半分になります。 システムは遠隔地にバックアップされているので、WAN接続は比較的遅くなる可能性があります。 トラフィックを半分にすると大きな利点があります。
結論
この場合、ネットワークのWANが最適化されるため、重複排除は効果的なソリューションとなります。
ユースケース3:ビジネスクリティカルなアプリケーションサーバ
環境
すべて異なるアプリケーションを持つ5つのアプリケーションサーバーをバックアップする必要がある。合計データ量は20TB。
重複排除の有効性
アプリケーションサーバーは、膨大な量のデータとさまざまなアプリケーションをホストします。 これは、重複があったとしてもごくわずかです。 さらに、バックアップおよび処理されるデータの総量が非常に多いです。
この場合、ストレージシステムは大量のデータのインデックスを作成しますが、重複がないため、ほとんどメリットがありません。 最悪の場合、1台のストレージシステムで1日にすべてのバックアップを処理できないことさえあります。
結論
この場合、重複排除は効果的ではありません。シンプルで大容量のネットワーク接続ストレージ(NAS)へのバックアップがより優れたソリューションとなります。
重複排除の総括
バックアップ重複排除テクノロジは、データをバックアップおよび転送するときに重複するデータブロックを排除することで、ストレージコストとネットワーク帯域幅の使用率を削減するのに役立ちます。
重複排除は、次のことに役立ちます。
- 固有のデータのみを格納することで、ストレージスペースの使用量を削減する
- データ重複排除固有のハードウェアに投資する必要性を排除
- 転送されるデータが少なくなるため、ネットワーク負荷が軽減され、生産タスクの帯域幅が広くなる
ただし、重複排除されたストレージにはRAMやCPUなどのコンピューティングリソースがさらに必要になる可能性があることを失念しないようにしましょう。一部の使用例では上記のとおり、従来の重複排除されていないストレージの方が、重複排除よりもコスト効率が高い場合もあります。重複排除を実装する前に、常にニーズとインフラストラクチャの分析が必要です。
Acronis について
Acronis は、2003 年にシンガポールで設立されたスイスの企業で、世界 15ヵ国にオフィスを構え、50ヵ国以上で従業員を雇用しています。Acronis Cyber Protect Cloud は、150の国の26の言語で提供されており、21,000を超えるサービスプロバイダーがこれを使って、750,000 以上の企業を保護しています。



