Deduplication at source
When performing a backup to a deduplicating vault, Acronis Backup & Recovery 11.5 Agent calculates a fingerprint of each data block. Such a fingerprint is often called a hash value.
Before sending the data block to the vault, the agent queries the deduplication database to determine whether the block's hash value is the same as that of an already stored block. If so, the agent sends only the hash value; otherwise, it sends the block itself. The storage node saves the received data blocks in a temporary file.
Some data, such as encrypted files or disk blocks of a non-standard size, cannot be deduplicated. The agent always transfers such data to the vault without calculating the hash values. For more information about restrictions of deduplication, see Deduplication restrictions.
Once the backup process is completed, the vault contains the resulting backup and the temporary file with the unique data blocks. The temporary file will be processed on the next stage. The backup (TIB file) contains hash values and the data that cannot be deduplicated. Further processing of this backup is not needed. You can readily recover data from it.
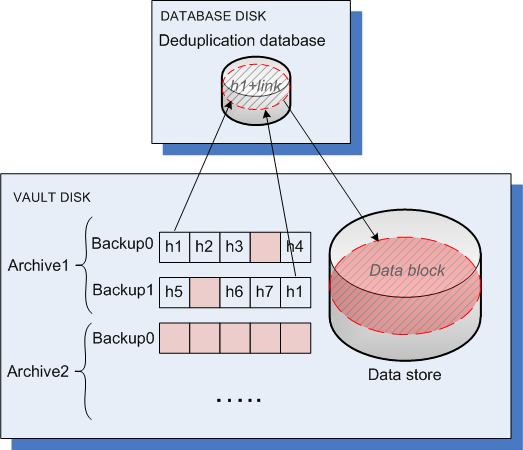
Deduplication at target
After a backup to a deduplicating vault is completed, the storage node runs the indexing activity. This activity deduplicates the data in the vault as follows:
As a result, the data store contains a number of unique data blocks. Each block has one or more references from the backups. The references are contained in the deduplication database. The backups remained untouched. They contain hash values and the data that cannot be deduplicated.
The following diagram illustrates the result of deduplication at target.
The indexing activity may take considerable time to complete. You can view this activity's state on the management server, by selecting the corresponding storage node and clicking View details. You can also manually start or stop this activity in that window.
Compacting
After one or more backups or archives have been deleted from the vault—either manually or during cleanup—the data store may contain blocks which are no longer referred to from any archive. Such blocks are deleted by the compacting task, which is a scheduled task performed by the storage node.
By default, the compacting task runs every Sunday night at 03:00. You can re-schedule the task by selecting the corresponding storage node, clicking View details, and then clicking Compacting schedule. You can also manually start or stop the task on that tab.
Because deletion of unused blocks is resource-consuming, the compacting task performs it only when a sufficient amount of data to delete has accumulated. The threshold is determined by the Compacting Trigger Threshold configuration parameter.